Eric Moskowitz
Harvard Staff Writer
Humans still doing the heavy lifting
Harvard Staff Writer

Amid claims of rapid advancement for AI’s mathematical prowess, the project known as “First Proof” gained widespread attention in February as a novel experiment to independently test AI’s ability to solve tough problems.
The organizers, including Harvard professor Lauren Williams, collected 10 problems known as “lemmas” — a theorem solved on the way to a larger proof — from leading mathematicians who had solved them but not yet published their answers, meaning no large-language model (LLM) could scrape the internet for easy solutions. They posted those problems online and gave AI companies and the public a week to tackle them.
Collectively, the LLMs solved at least six of 10, with results as mixed as they were intriguing. The organizers had intended First Proof to be a nimble experiment — with no funding and no formal grading process — save for a real-time message board where mathematicians could discuss the solutions. But they soon discovered that some of those solutions were nearly impossible to vet for correctness. At the same time, it could be hard to tell in some cases how much work had been done autonomously by AI as opposed to the mathematicians guiding or coaxing it.
They knew they wanted to try again, with a formalized structure — a newly registered nonprofit, First Proof Foundation Inc. — more transparency, and more controls for the next round, which they dubbed “First Proof, Second Batch.” That included running the tests themselves and checking all of the answers carefully with human referees.
“We wanted to structure the second batch as a more formal benchmark, where transparency was really a key thing,” said Williams, Dwight Parker Robinson Professor of Mathematics and a 2025 MacArthur Foundation “genius grant” recipient.
They also turned down offers to test the most cutting-edge internal AI models, limiting the experiment to commercially available frontier systems (like ChatGPT Pro) or to “harnesses” that have also been made available to the public, meaning systems that scaffold multiple LLMs together so they can talk to each other to persist through complex problems.
“We felt strongly that if we’re going to be doing a public service for mathematicians and the community, we need to test publicly available models,” Williams said. The results for this new round of 10 questions are now out, after two days of rigorous refereeing by 30 living, breathing mathematicians at Harvard’s Center of Mathematical Sciences and Applications on June 4 and 5. (For the sanctity of the experiment, no photographers were allowed in, and referees’ names are being kept anonymous.) The researchers released the results in a webinar on June 10 and a 36-page online report.
This time the mathematicians picked problems with human solutions of up to eight pages (previously it was five) from diverse areas of the field, while limiting the AI systems to 24 hours instead of a week to do their work. And, instead of that computing happening behind the scenes at AI firms, the researchers ran each query themselves.
They tested OpenAI’s ChatGPT 5.5 Pro as well as three harnesses specifically designed for math and developed by academic teams at UCLA, Princeton, and jointly at ETH Zurich in Switzerland and Aarhus University in Denmark.
The researchers considered human referees essential, given the unconventional paths AI can take on the route to solving a problem as well as its potential for hallucinating answers. Contributions from three academic institutes (including Harvard’s CMSA) and multiple foundations, as well as from Anthropic and OpenAI, offset the costs of the experiment, but the corporate AI money came with no strings, and First Proof’s editorial board and directors received no compensation. The testers ran the submissions through the models without knowing which AI system they were using (they called them A, B, C, and D); the referees reviewed the answers in similarly blind fashion.
Two or three referees reviewed each question — depending on its intricacy — and assigned one of four grades: essentially flawless, publishable with minor revisions, publishable with major revisions, or rejected. For those earning middle grades, they distinguished whether the issues needing revision were mathematical mistakes or inadequate citations, even though all AIs queried were prompted to carefully cite their answers.
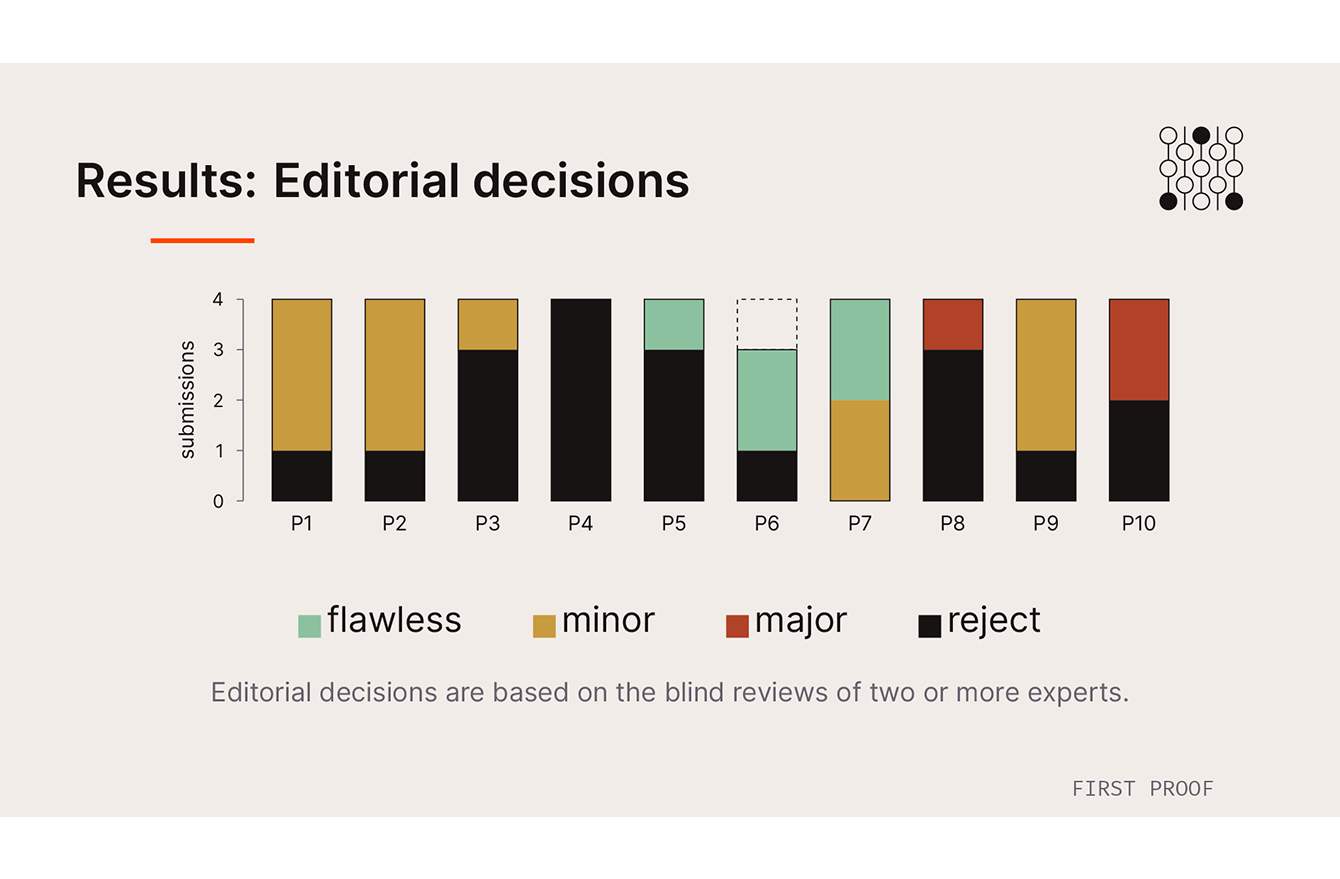
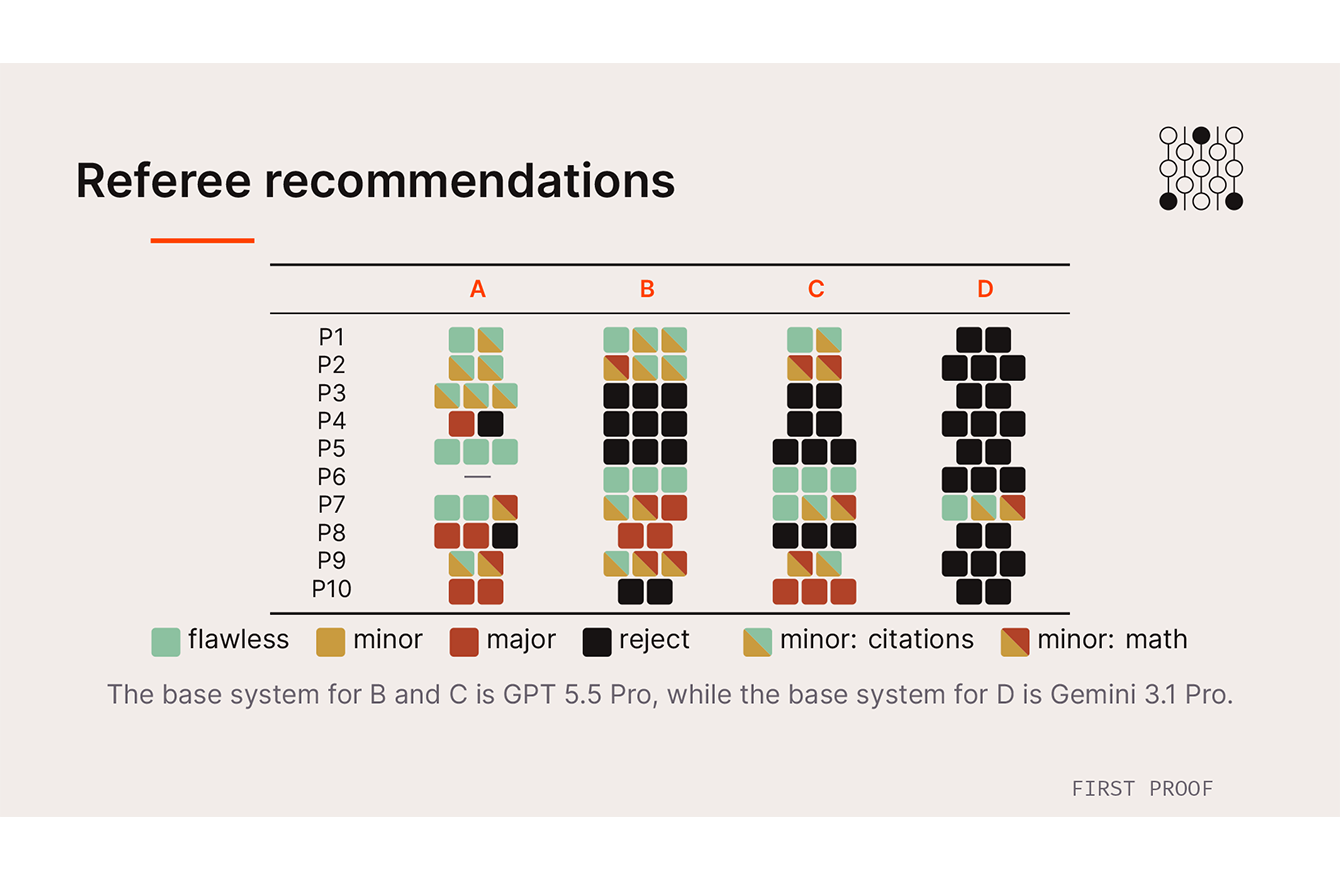
The systems provided a wide range of results, in terms of their success rates and of the ways they approached the problems and cited — or failed to cite — their answers.
“Since we formally graded the solutions, we were able to get a really clear picture of how the LLMs did,” Williams said. “A few solutions were correct and novel, with proofs that were significantly different than those of the human authors.”
Others were correct and solved at a high level, in a similar way to a published paper. Some were correct but were so strange or clunky they took hours for a mathematician to decipher. Some were mathematically correct, but cribbed so closely from published works without citing them that they would have been rejected for plagiarism — even though the AI systems had all been prompted to include full citations. And other answers were simply wrong.
The experiment also considered the computing costs per question. System B (the UCLA harness) ran up nearly $4,800 computing charges while taking almost the full 24 hours to return some answers. ChatGPT 5.5 Pro responded with answers in a fraction of the time for $117, while still solving several problems correctly. The European harness (system A) was the most successful, but it wrestled with some problems for 23 hours and ran up a $3,186 tab.
Nikhil Srivastava of the University of California, Berkeley, a First Proof co-editor, said the referees noticed an unusual “texture” to some of the answers, with abundant citations for routine steps but less detail for the most difficult parts.
To that end, one of the main Second Batch findings was not AI’s math prowess but “how hard it is to check these solutions,” requiring considerable human attention, said Stanford University’s Mohammed Abouzaid, who conceived of First Proof with co-editor Rachel Ward of the University of Texas at Austin, then invited Williams and Srivastava to develop the project.
With AI advancing rapidly, First Proof plans to run more tests, including an informal “community experiment” in a few weeks, followed by the next formal batch of testing planned for the end of the summer.
In both the webinar and the report, the researchers emphasized that research math is an “inherently creative discipline, in which mathematicians push the boundary of mathematics by asking new questions and developing frameworks to answer these questions.” They likened it to art, quoting conceptual artist Sol LeWitt on the notion that “the idea or concept is the most important aspect of the work.”
In that mathematical triumvirate — asking questions, developing frameworks to answer them, and then trying to solve those questions — AI has so far only demonstrated aptitude at the last part, Srivastava said.
A colleague, he said, used AI “to generate 100 questions over the span of a few months, and one of them was really good. So that’s something.”

Prospective buyers are most concerned about where to plug in, researchers say

Annual program celebrated staff members for work ethic, service to students, dedication to mission

FAS Dean Hopi Hoekstra helped dedicate a plaque at the teenage home of Cecilia Payne-Gaposchkin.